How to fetch data in React with performance in mind
Deep dive into data fetching in React.
What do we mean by performant react app, fundamental libraries-agnostic patterns and techniques, how react lifecycle and browser limitations affect data fetching and apps rendering time and order.
Nadia Makarevich

Have you tried recently to wrap your head around what’s the latest on data fetching in React? I tried. Almost lost my mind in the process. The chaos of endless data management libraries, GraphQL or not GraphQL, recent React 18 & useEffect scandal, useEffect is evil since it causes waterfalls, Suspense for data fetching is supposed to save the world, but is still marked as Experimental, fetch-on-render, fetch-then-render and render-as-you-fetch patterns that confuse even people who write about them. What on Earth is going on? Why do I suddenly need a PhD to just make a simple GET request? 😭
And what is the actual “right way” to fetch data in React now?
Let’s take a look.
Types of data fetching
Generally speaking, in the modern frontend world, we can loosely separate the concept of “data fetching” into two categories: initial data fetching and data fetching on demand.
Data on demand is something that you fetch after a user interacts with a page, in order to update their experience. All the various autocompletes, dynamic forms, and search experiences fall under that category. In React, fetch of this data is usually triggered in callbacks.
Initial data is the data you’d expect to see on a page right away when you open it. It’s the data we need to fetch before a component ends up on the screen. It’s something that we need to be able to show users some meaningful experience as soon as possible. In React, fetching data like this usually happens in useEffect (or in componentDidMount for class components).
Interestingly enough, although those concepts seem totally different, the core principles and fundamental patterns of data fetching are exactly the same for them both. But the initial data fetching is usually the most crucial for the majority of people. During this stage, the first impression of your apps as “slow as hell” or “blazing fast” will form. That’s why for the rest of the article I will be focusing solely on initial data fetching and how to do it properly with performance in mind.
Do I really need an external library to fetch data in
React?
First thing first. External libraries for data fetching in React - yes or no?
Short answer - no. And yes. Depends on your use case 😅 If you actually just need to fetch a bit of data once and forget about it, then no, you don’t need anything. Just a simple fetch in useEffect hook will do just fine:
const Component = () => {const [data, setData] = useState();useEffect(() => {// fetch dataconst dataFetch = async () => {const data = await (await fetch('https://run.mocky.io/v3/d6155d63-938f-484c-8d87-6f918f126cd4',)).json();// set state when the data receivedsetData(data);};dataFetch();}, []);return <>...</>;};
But as soon as your use case exceeds “fetch once and forget” you’re going to face tough questions. What about error handling? What if multiple components want to fetch data from this exact endpoint? Do I cache that data? For how long? What about race conditions? What if I want to remove the component from the screen? Should I cancel this request? What about memory leaks? And so on and so forth. Dan Abramov explained the situation really well, highly recommend reading for more details.
Not a single question from that list is even React specific, it’s a general problem of fetching data over the network. And to solve those problems (and more!) there are only two paths: you either need to re-invent the wheel and write a lot of code to solve those, or just rely on some existing library that has been doing this for years.
Some libraries, like axios, will abstract some concerns, like canceling requests, but will have no opinion on React-specific API. Others, like swr, will handle pretty much everything for you, including caching. But essentially, the choice of technology doesn’t matter much here. No library or Suspense in the world can improve performance of your app just by itself. They just make some things easier at the cost of making some things harder. You always need to understand the fundamentals of data fetching and data orchestration patterns and techniques in order to write performant apps.
What is a “performant” React app?
Before jumping into concrete patterns and code examples, let’s have a conversation on what “performance” of an app is. How do you know whether an app is “performant”? It’s relatively straightforward with a simple component: you just measure how long it takes to render it, and voila! The smaller the number, the more “performant” (i.e. faster) your component is.
With async operations, which data fetching typically is, and in the context of big apps and user experience point of view it’s not that obvious.
Imagine we were implementing an issue view for an issue tracker. It would have sidebar navigation on the left with a bunch of links; the main issue information in the center - things like title, description or assignee; and a section with comments underneath that.
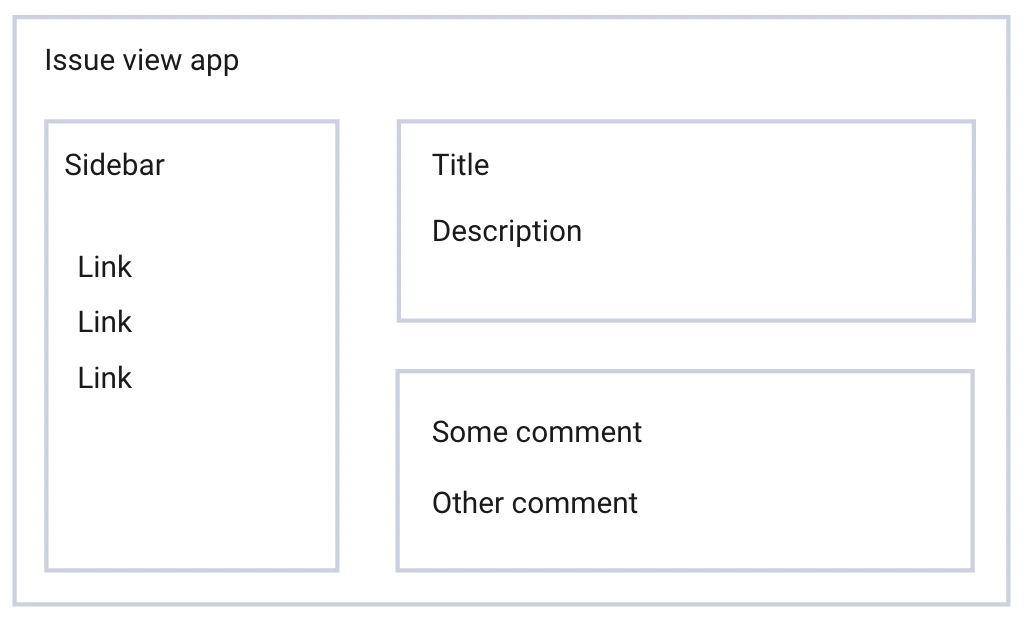
And let’s say the app is implemented in three different ways:
- Shows a loading state until all the data is loaded, and then renders everything in one go. Takes ~3 seconds.
- Shows a loading state until sidebar data is loaded first, renders sidebar, and keeps loading state until the data is finished in the main part. The sidebar to appear takes ~1 second, the rest of the app appears in ~3 seconds. Overall takes ~ 4 seconds.
- Shows a loading state until main issue data is loaded, renders it, keeps loading state for sidebar and comments. When sidebar loaded - renders it, comments are still in loading state. Main part appears in ~2 seconds, sidebar in ~1 second after that, takes another ~2 second for comments to appear. Overall takes ~5s to appear.
Which app is the most performant here? What do you think?
Play around with the apps One, Two and Three and make a decision before scrolling to the answer.
…
…
…
And the answer is of course tricky, and the most performant app is not the one that you chose, but… None of them. Or all of them. Or any of them. It depends.
The first app loads in just 3 seconds - the fastest of them all. From the pure numbers perspective, it’s a clear winner. But it doesn’t show anything to users for 3 seconds - the longest of them all. Clear loser?
The second app loads something on the screen (Sidebar) in just 1 second. From the perspective of showing at least something as fast as possible, it’s a clear winner. But it’s the longest of them all to show the main part of the issue. Clear loser?
The third app loads the Issue information first. From the perspective of showing the main piece of the app first, it’s a clear winner. But the “natural” flow of information for left-to-right languages is from the top-left to the bottom-right. This is how we read usually. This app violates it and it makes the experience the most “junky” one here. Not to mention it’s the longest of them all to load. Clear loser?
It always depends on the message you’re trying to convey to the users. Think of yourself as a storyteller, and the app is your story. What is the most important piece of the story? What is the second? Does your story have a flow? Can you even tell it in pieces, or you want your users to see the story in full right away, without any intermediate steps?
When, and only when, you have an idea of what your story should look like, then it will be the time to assemble the app and optimize the story to be as fast as possible. And the true power comes here not from various libraries, Graphql or Suspense, but from the knowledge of:
- when is it okay to start fetching data?
- what can we do while the data fetching is in the progress?
- what should we do when the data fetching is done?
and knowing a few techniques that allow you to control all three stages of the data fetching requests.
But before jumping into actual techniques, we need to understand two more very fundamental things: React lifecycle and browser resources and their influence on our goal.
React lifecycle and data fetching
The most important thing to know and remember, when planning your fetch requests strategy, is when React component’s lifecycle is triggered. Check out this code:
const Child = () => {useEffect(() => {// do something here, like fetching data for the Child}, []);return <div>Some child</div>;};const Parent = () => {// set loading to true initiallyconst [isLoading, setIsLoading] = useState(true);if (isLoading) return 'loading';return <Child />;};
We have our Parent component, it conditionally renders Child component based on state. Will Child’s useEffect , and therefore the fetch request there, be triggered here? The intuitive answer here is the correct one - it won’t. Only after Parent’s isLoading state changes to false, will the rendering and all other effects be triggered in the Child component.
What about this code for the Parent:
const Parent = () => {// set loading to true initiallyconst [isLoading, setIsLoading] = useState(true);// child is now here! before returnconst child = <Child />;if (isLoading) return 'loading';return child;};
Functionality is the same: if isLoading set to false show Child, if true - show the loading state. But the <Child /> element this time is before the if condition. Will the useEffect in Child be triggered this time? And the answer is now less intuitive, and I’ve seen a lot of people stumble here. The answer is still the same - no, it won't.
When we write const child = <Child /> we don’t “render” Child component. <Child /> is nothing more than a syntax sugar for a function that creates a description of a future element. It only is rendered when this description ends up in the actual visible render tree - i.e. returned from the component. Until then it just sits there idly as one massive object and does nothing.
If you want to understand in more detail and with code examples how it works and all the possible edge cases, this article might be interesting to you: The mystery of React Element, children, parents and re-renders.
There are more things to know about React lifecycle of course: the order in which all of this is triggered, what is triggered before or after painting, what slows down what and how, useLayoutEffect hook, etc. But all of this becomes relevant much much later, when you orchestrated everything perfectly already and now fighting for milliseconds in a very big complicated app. So a topic for another article, otherwise this one will turn into a book.
Browser limitations and data fetching
You might be thinking at this point: gosh, it’s so complicated. Can’t we just fire all the requests as soon as possible, shove that data in some global store, and then just use it when it’s available? Why even bother with the lifecycle and orchestration of anything?
I feel ya. And sure, we can do it, if the app is simple and only have a few requests to make ever. But in large apps, where we can have dozens of data fetching requests, that strategy can backfire. And I’m not even talking about server load and whether it can handle it. Let’s assume that it can. The problem is that our browsers can’t!
Did you know, that browsers have a limit on how many requests in parallel to the same host they can handle? Assuming the server is HTTP1 (which is still 70% of the internet), the number is not that big. In Chrome it’s just 6. 6 requests in parallel! If you fire more at the same time, all the rest of them will have to queue and wait for the first available “slot”.
And 6 requests for initial data fetching in a big app is not unreasonable. Our very simple “issue tracker” already has 3, and we haven’t even implemented anything of value yet. Imagine all the angry looks you’ll get, if you just add a somewhat slow analytics request that literally does nothing at the very beginning of the app, and it ends up slowing down the entire experience.
Wanna see it in action? Here’s the simplest code:
const App = () => {// I extracted fetching and useEffect into a hookconst { data } = useData('/fetch-some-data');if (!data) return 'loading...';return <div>I'm an app</div>;};
Assume that fetch request is super fast there, takes just ~50ms. If I add just 6 requests before that app that take 10 seconds, without waiting for them or resolving them, the whole app load will take those 10 seconds (in Chrome of course).
// no waiting, no resolving, just fetch and drop itfetch('https://some-url.com/url1');fetch('https://some-url.com/url2');fetch('https://some-url.com/url3');fetch('https://some-url.com/url4');fetch('https://some-url.com/url5');fetch('https://some-url.com/url6');const App = () => {... same app code}
See it in codesandbox and play around with how just removing one of those useless fetches makes the difference.
Requests waterfalls: how they appear
Finally, time to do some serious coding! Now that we have all the needed moving pieces and know how they fit together, time to write the story of our Issue tracking app. Let’s implement those examples from the beginning of the article, and see what is possible.
Let’s start with laying out components first, then wire the data fetching afterward. We’ll have the app component itself, it will render Sidebar and Issue, and Issue will render Comments.
const App = () => {return (<><Sidebar /><Issue /></>);};const Sidebar = () => {return; // some sidebar links};const Issue = () => {return (<>// some issue data<Comments /></>);};const Comments = () => {return; // some issue comments};
Now to the data fetching. Let’s first extract the actual fetch and useEffect and state management into a nice hook, to simplify the examples:
export const useData = (url) => {const [state, setState] = useState();useEffect(() => {const dataFetch = async () => {const data = await (await fetch(url)).json();setState(data);};dataFetch();}, [url]);return { data: state };};
Then, I would probably naturally want to co-locate fetching requests with the bigger components: issue data in Issue and comments list in Comments. And would want to show the loading state while we’re waiting of course!
const Comments = () => {// fetch is triggered in useEffect there, as normalconst { data } = useData('/get-comments');// show loading state while waiting for the dataif (!data) return 'loading';// rendering comments now that we have access to them!return data.map((comment) => <div>{comment.title}</div>);};
And exactly the same code for Issue, only it will render Comments component after loading:
const Issue = () => {// fetch is triggered in useEffect there, as normalconst { data } = useData('/get-issue');// show loading state while waiting for the dataif (!data) return 'loading';// render actual issue now that the data is here!return (<div><h3>{data.title}</h3><p>{data.description}</p><Comments /></div>);};
And the app itself:
const App = () => {// fetch is triggered in useEffect there, as normalconst { data } = useData('/get-sidebar');// show loading state while waiting for the dataif (!data) return 'loading';return (<><Sidebar data={data} /><Issue /></>);};
Boom, done! Check out the actual implementation in codesandbox. Have you noticed how sloooow it is? Slower than all our examples from above!
What we did here is implemented a classic waterfall of requests. Remember the react lifecycle part? Only components that are actually returned will be mounted, rendered, and as a result, will trigger useEffect and data fetching in it. In our case, every single component returns "loading" state while it waits for data. And only when data is loaded, does they switch to a component next in the render tree, it triggers its own data fetching, returns “loading” state and the cycle repeats itself.
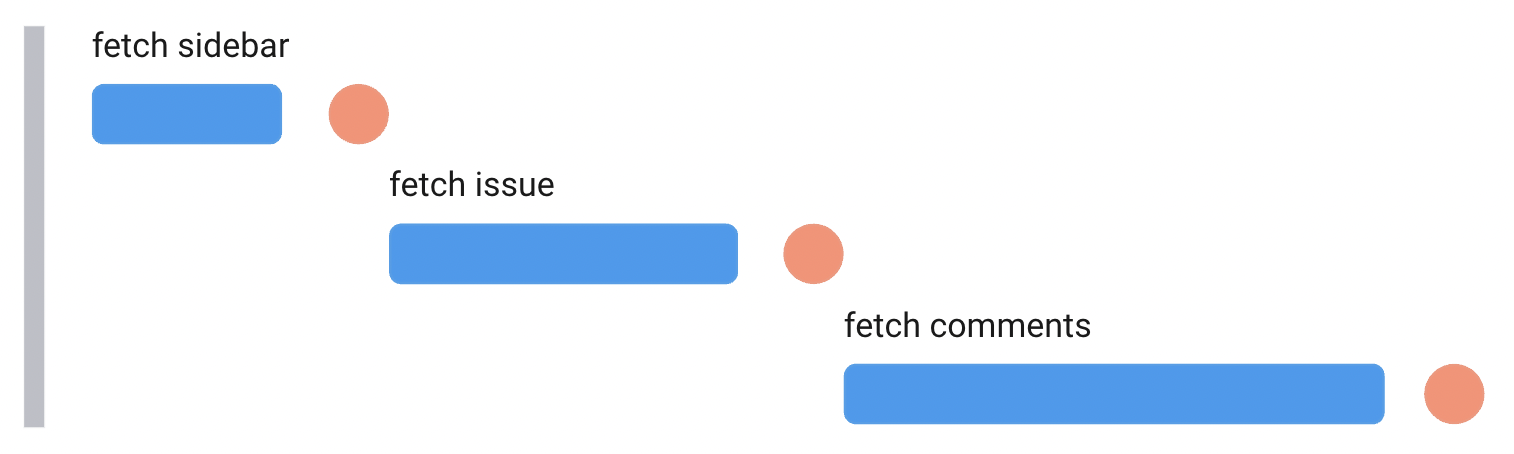
Waterfalls like that are not the best solution when you need to show the app as fast as possible. Likely, there are a few ways to deal with them (but not Suspense, about that one later).
How to solve requests waterfall
Promise.all solution
The first and easiest solution is to pull all those data fetching requests as high in the render tree as possible. In our case, it’s our root component App. But there is a catch there: you can’t just “move” them and leave as-is. We can’t just do something like this:
useEffect(async () => {const sidebar = await fetch('/get-sidebar');const issue = await fetch('/get-issue');const comments = await fetch('/get-comments');}, []);
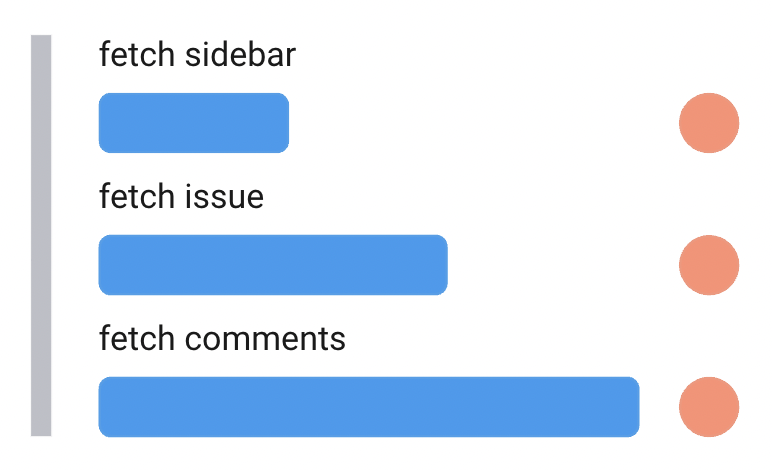
This is just yet another waterfall, only co-located in a single component: we fetch sidebar data, await for it, then fetch issue, await, fetch comments, await. The time when all the data will be available for render will be the sum of all those waiting times: 1s + 2s + 3s = 6 seconds. Instead, we need to fire them all at the same time, so that they are sent in parallel. That way we will be waiting for all of them no longer than the longest of them: 3 seconds. 50% performance improvement!
One way to do it is to use Promise.all:
useEffect(async () => {const [sidebar, issue, comments] = await Promise.all([fetch('/get-sidebar'),fetch('/get-issue'),fetch('/get-comments'),]);}, []);
and then save all of them to state in the parent component and pass them down to the children components as props:
const useAllData = () => {const [sidebar, setSidebar] = useState();const [comments, setComments] = useState();const [issue, setIssue] = useState();useEffect(() => {const dataFetch = async () => {// waiting for allthethings in parallelconst result = (await Promise.all([fetch(sidebarUrl),fetch(issueUrl),fetch(commentsUrl),])).map((r) => r.json());// and waiting a bit more - fetch API is cumbersomeconst [sidebarResult, issueResult, commentsResult] =await Promise.all(result);// when the data is ready, save it to statesetSidebar(sidebarResult);setIssue(issueResult);setComments(commentsResult);};dataFetch();}, []);return { sidebar, comments, issue };};const App = () => {// all the fetches were triggered in parallelconst { sidebar, comments, issue } = useAllData();// show loading state while waiting for all the dataif (!sidebar || !comments || !issue) return 'loading';// render the actual app here and pass data from state to childrenreturn (<><Sidebar data={sidebar} /><Issue comments={comments} issue={issue} /></>);};
This is how the very first app from the test at the beginning is implemented.
Parallel promises solution
But what if we don’t want to wait for them all? Our comments are the slowest and the least important part of the page, it doesn’t make much sense to block rendering of the sidebar while we’re waiting for them. Can I fire all requests in parallel, but wait for them independently?
Of course! We just need to transform those fetch from async/await syntax to proper old-fashioned promises and save the data inside then callback:
fetch('/get-sidebar').then((data) => data.json()).then((data) => setSidebar(data));fetch('/get-issue').then((data) => data.json()).then((data) => setIssue(data));fetch('/get-comments').then((data) => data.json()).then((data) => setComments(data));
Now every fetch request is fired in parallel but resolved independently. And now in the App’s render we can do pretty cool things, like render Sidebar and Issue as soon as their data ends up in the state:
const App = () => {const { sidebar, issue, comments } = useAllData();// show loading state while waiting for sidebarif (!sidebar) return 'loading';// render sidebar as soon as its data is available// but show loading state instead of issue and comments while we're waiting for themreturn (<><Sidebar data={sidebar} /><!-- render local loading state for issue here if its data not available --><!-- inside Issue component we'd have to render 'loading' for empty comments as well -->{issue ? <Issue comments={comments} issue={issue} /> : 'loading''}</>)}
In here, we render Sidebar, Issue and Comments components as soon as their data becomes available - exactly the same behavior as the initial waterfall. But since we fired those requests in parallel, the overall waiting time will drop from 6 seconds to just 3 seconds. We just massively improved performance of the app, while keeping its behavior intact!

One thing to note here, is that in this solution we’re triggering state change three times independently, which will cause three re-render of the parent component. And considering that it’s happening at the top of the app, unnecessary re-render like this might cause half of the app to re-render unnecessarily. The performance impact really depends on the order of your components of course and how big they are, but something to keep in mind. A helpful guide on how to deal with re-renders is here: React re-renders guide: everything, all at once
Data providers to abstract away fetching
Lifting data loading up like in the examples above, although good for performance, is terrible for app architecture and code readability. Suddenly, instead of nicely co-located data fetching requests and their components we have one giant component that fetches everything and massive props drilling throughout the entire app.
Likely, there is an easy(ish) solution to this: we can introduce the concept of “data providers” to the app. “Data provider” here would be just an abstraction around data fetching that gives us the ability to fetch data in one place of the app and access that data in another, bypassing all components in between. Essentially like a mini-caching layer per request. In “raw” React it’s just a simple context:
const Context = React.createContext();export const CommentsDataProvider = ({ children }) => {const [comments, setComments] = useState();useEffect(async () => {fetch('/get-comments').then((data) => data.json()).then((data) => setComments(data));}, []);return (<Context.Provider value={comments}>{children}</Context.Provider>);};export const useComments = () => useContext(Context);
Exactly the same logic for all three of our requests. And then our monster App component turns into something as simple as this:
const App = () => {const sidebar = useSidebar();const issue = useIssue();// show loading state while waiting for sidebarif (!sidebar) return 'loading';// no more props drilling for any of thosereturn (<><Sidebar />{issue ? <Issue /> : 'loading''}</>)}
Our three providers will wrap the App component and will fire fetching requests as soon as they are mounted in parallel:
export const VeryRootApp = () => {return (<SidebarDataProvider><IssueDataProvider><CommentsDataProvider><App /></CommentsDataProvider></IssueDataProvider></SidebarDataProvider>);};
And then in something like Comments (i.e. far far deep into the render tree from the root app) we’ll just access that data from “data provider”:
const Comments = () => {// Look! No props drilling!const comments = useComments();};
If you’re not a huge fan of Context - not to worry, exactly the same concept will work with any state management solution of your choosing. And if you want to give Context a try, check out this article: How to write performant React apps with Context, it has some patterns for Context-related performance.
What if I fetch data before React?
One final trick to learn about waterfalls fighting. That one is very important to know so that you can stop your colleagues from using it during PR reviews 😅 . What I’m trying to say here: it’s a very dangerous thing to do, use it wisely.
Let’s take a look at our Comments component from the times we implemented the very first waterfall, the one that was fetching data by itself (I moved the getData hook inside).
const Comments = () => {const [data, setData] = useState();useEffect(() => {const dataFetch = async () => {const data = await (await fetch('/get-comments')).json();setData(data);};dataFetch();}, [url]);if (!data) return 'loading';return data.map((comment) => <div>{comment.title}</div>);};
And pay special attention to the 6th line there. What is fetch('/get-comments')? It’s nothing more than just a promise, that we await inside our useEffect. It doesn’t depend on anything of React in this case - no props, state or internal variables dependencies. So what will happen if I just move it to the very top, before I even declare Comments component? And then just await that promise inside useEffect hook?
const commentsPromise = fetch('/get-comments');const Comments = () => {useEffect(() => {const dataFetch = async () => {// just await the variable hereconst data = await (await commentsPromise).json();setState(data);};dataFetch();}, [url]);};
Really fancy thing: our fetch call basically “escapes” all React lifecycle and will be fired as soon as javascript is loaded on the page, before any of useEffect anywere are called. Even before the very first request in the roop App component will be called. It will be fired, javascript will move on to other things to process, and the data will just sit there quietly until someone actually resolves it. Which is what we’re doing in our useEffect in Comments.
Remember our initial waterfall pic?
Just moving fetch call outside of Comments resulted in this instead:

Technically speaking, we could’ve just moved all of our promises outside of components, that would’ve solved the waterfalls and we wouldn’t have to deal with lifting fetching up or data providers.
So why didn’t we? And why it’s not a very common pattern?
Easy. Remember the Browsers limitation chapter? Only 6 requests in parallel, the next one will queue. And fetches like that will be fired immediately and completely uncontrollably. A component that fetches heavy data and rendered once in a blue moon, in your app with “traditional” waterfall approach won’t bother anyone until it’s actually rendered. But with this hack, it has the potential to steal the most valuable milliseconds of initial fetching of critical data. And good luck to anyone who’s trying to figure out how a component that sits in some existential corner of the code and is never even rendered on a screen can slow down the entire app.
There are only two “legit” use cases that I can think of for that pattern: pre-fetching of some critical resources on the router level and pre-fetching data in lazy-loaded components.
In the first one, you actually need to fetch data as soon as possible, and you know for sure that the data is critical and required immediately. And lazy-loaded components' javascript will be downloaded and executed only when they end up in the render tree, so by definition after all the critical data is fetched and rendered. So it’s safe.
What if I use libraries for data fetching?
Up until now in all code examples, I’ve been using only native fetch. This is on purpose: I wanted to show you fundamental data fetching patterns in React, and those are libraries-independent. Regardless of any library you’re using or want to use, the principle of waterfalls, fetching data within or outside of React lifecycle stays the same.
React-independent libraries like Axios just abstract away the complexities of dealing with actual fetch, nothing more. I can replace all fetch with axios.get in the examples and the result will stay the same.
React-integrated libraries with hooks and query-like API like swr in addition abstract away dealing with useCallback, state, and many other things like error handling and caching. Instead of this monstrosity of a code that still needs a lot of things to be production-ready:
const Comments = () => {const [data, setData] = useState();useEffect(() => {const dataFetch = async () => {const data = await (await fetch('/get-comments')).json();setState(data);};dataFetch();}, [url]);// the rest of comments code};
with swr I can just write this:
const Comments = () => {const { data } = useSWR('/get-comments', fetcher);// the rest of comments code};
Underneath, all of them will use useEffect or equivalent to fetch the data, and state to update the data and trigger re-render of the host component.
What about Suspense?
The data fetching in React story without at least mentioning Suspense would be incomplete 😅 So, what about Suspense? Well, nothing. At the time of writing the article, Suspense for data fetching is still flagged as Experimental, so I would not recommend using it in anything remotely production-related.
But let’s imagine that the API will stay the same and it will become production-ready tomorrow. Will it fundamentally solve data fetching and will it make everything above obsolete? Not at all. We are still going to be bound by browsers resources limit, React lifecycle, and the nature of requests waterfalls as a result.
Suspense is just a really fancy and clever way to replace fiddling with loading states. Instead of this:
const Comments = ({ commments }) => {if (!comments) return 'loading';// render comments};
we’re just going to lift that loading state up and do this:
const Issue = () => {return (<>// issue data<Suspense fallback="loading"><Comments /></Suspense></>);};
This is a really nice article if you want to start building with Suspense already: Experimental React: Using Suspense for data fetching - LogRocket Blog. Just don’t forget all the core principles and limitations from the above when suspending stuff.
Huh, that was a lot to cover for me and digest for you. Hope you are not going to see waterfalls in your sleep (I definitely see them now!). Little things to take away:
- you don’t have to have a library to fetch data in React, but they help
- performance is subjective and always depends on user experience
- browser resources available to you are limited, just 6 requests in parallel. Don’t go wild with pre-fetching the world
- useEffect doesn’t cause waterfalls by itself, they are just a natural consequence of composition and loading state
Have a great fetching experience and see you next time! 🐈⬛
Table of Contents
Want to learn even more?

Web Performance Fundamentals
A Frontend Developer’s Guide to Profile and Optimize React Web Apps

Advanced React
Deep dives, investigations, performance patterns and techniques.
Advanced React Mini-Course
Free YouTube mini-course following first seven chapters of the Advanced React book