React project structure for scale: decomposition, layers and hierarchy
How to organize React projects in a way that is scalable, structured, modular, consistent and logical.
Nadia Makarevich

How to structure React apps “the right way” seems to be the hot topic recently for as long as React existed. React’s official opinion on it is that it “doesn’t have opinions”. This is great, it gives us total freedom to do whatever we want. And also it’s bad. It leads to so many fundamentally different and very strong opinions about the proper React app structure, that even the most experienced developers sometimes feel lost, overwhelmed and the need to cry in a dark corner because of it.
I, of course, also have a strong opinion on the topic 😈. And it’s not even going to be “it depends” this time 😅 (almost). What I want to share today is the system, that I’ve seen working pretty well in:
- an environment with dozens of loosely connected teams in the same repository working on the same product
- in a fast-paced environment of a small startup with just a few engineers
- or even for one-person projects (yeah, I use it all the time for my personal stuff)
Just remember, same as the Pirate’s Code, all of this is more what you'd call "guidelines" than actual rules.
What do we need from the project structure convention
I don’t want to go into details on why we need conventions like this in the first place: if you landed on this article you probably already decided that you need it. What I want to talk about a little bit though, before jumping into solutions, is what makes a project structure convention great.
Replicability
Code convention should be understandable and easy enough to reproduce by any member of the team, including a recently joined intern with minimal React experience. If the way of working in your repo requires a PhD, a few months of training and deeply philosophical debates over every second PR… Well, it’s probably going to be a really beautiful system, but it won’t exist anywhere other than on paper.
Inferrability
You can write a book and shoot a few movies on “The way of working in our repo”. You can probably even convince everyone on the team to read and watch it (although you probably won't). The fact remains: most people are not going to memorise every word of it, if at all. For the convention to actually work, it should be so obvious and intuitive, so that people in the team ideally are able to reverse-engineer it by just reading the code. In the perfect world, same as with code comments, you wouldn’t even need to write it down anywhere - the code and structure itself would be your documentation.
Independence
One of the most important requirements from coding structure guidelines for multiple people, and especially multiple teams, is to solidify a way for developers to operate independently. The last thing that you want is multiple developers working on the same file, or teams constantly invading each other's areas of responsibility.
Therefore, our coding structure guidelines should provide such a structure, where teams are able to peacefully co-exist within the same repository.
Optimised for refactoring
Last one, but in the modern frontend world, it’s the most important one. Frontend today is incredibly fluid. Patterns, frameworks, and best practices are changing constantly. On top of that, we are expected to deliver features fast nowadays. No, FAST. And then re-write it completely after a month. And then maybe re-write it again.
So it becomes very important for our coding convention to not force us to “glue” the code in some permanent place with no way to move it around. It should organize things in such a way that refactoring is something that is performed casually on a daily basis. The worst thing a convention can do is to make refactoring so hard and time-consuming that everyone is terrified of it. Instead, it should be as simple as breathing.
Now, that we have our general requirements for the project structure convention, time to go into details. Let’s start with the big picture, and then drill down into the details.
Organising the project itself: decomposition
The first and the most important part of organizing a large project that is aligned with the principles we defined above is “decomposition”: instead of thinking of it as a monolithic project, it can be thought of as a composition of more or less independent features. Good old “monolith” vs “microservices” discussion, only within one React application. With this approach every feature is essentially a “nanoservice” in a way, that is isolated from the rest of the features and communicates with them through an external “API” (usually just React props).
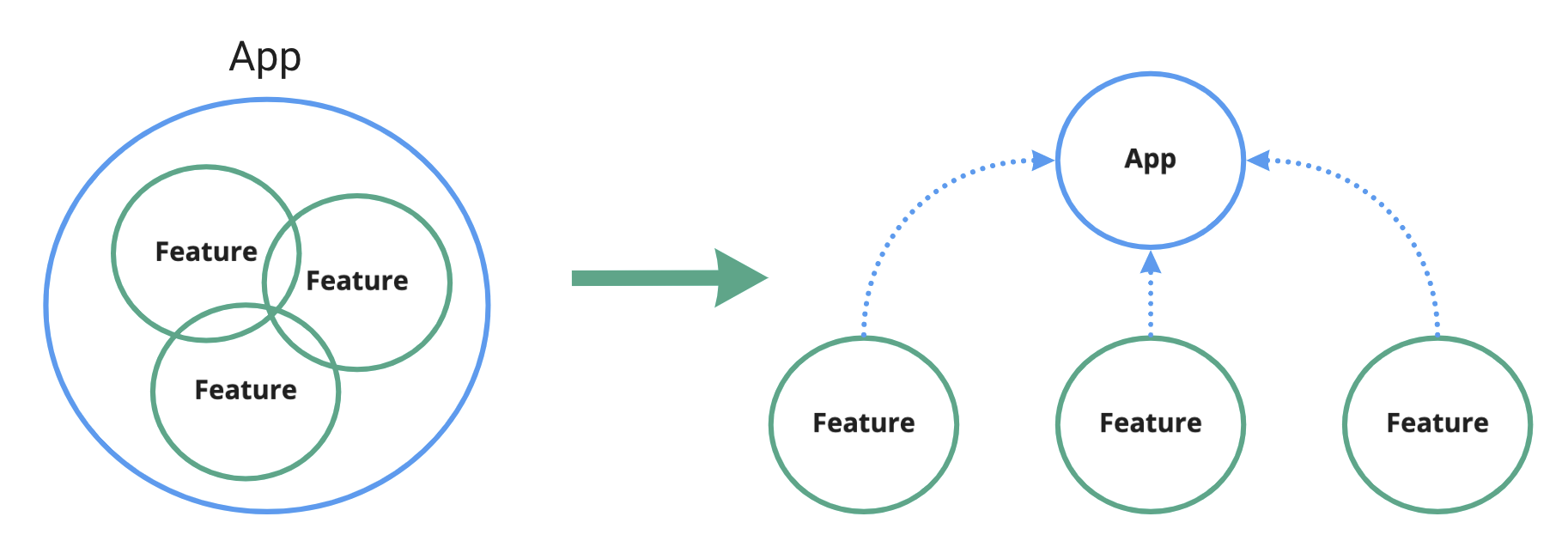
Even just following this mindset, compared to the more traditional “React project” approach, will give you pretty much everything from our list above: teams/people will be able to work independently on features in parallel if they implement them as a bunch of “black boxes” plugged into each other. If the set-up is right, it should be pretty obvious for anyone as well, just would require a bit of practice to adjust to the mind shift. If you need to remove a feature you can just “un-plug” it, or replace it with another feature. Or if you need to refactor the internals of a feature, you can do it. And as long as the public “API” of it stays functional no one outside will even notice it.
I’m describing a React component, isn’t it? 😅 Well, the concept is the same, and this makes React perfect for this mindset. I would define a “feature”, to distinguish it from a “component”, as “a bunch of components and other elements tied together in a complete from an end-user perspective functionality”.
Now, how to organise this for a single project? Especially considering, that compare to microservices, it should come with much less plumbing: in a project with hundreds of features, extracting them all into actual microservices will be close to impossible. What we can do instead, is to use multi-package monorepo architecture: it’s perfect for organizing and isolating independent features as packages. A package is a concept that should be already familiar to anyone who installed anything from npm. And a monorepo - is just a repo, where you have source code of multiple packages living together in harmony, sharing tools, scripts, dependencies and sometimes each other.
So the concept is simple: React project → split it into independent features → place those features into packages.
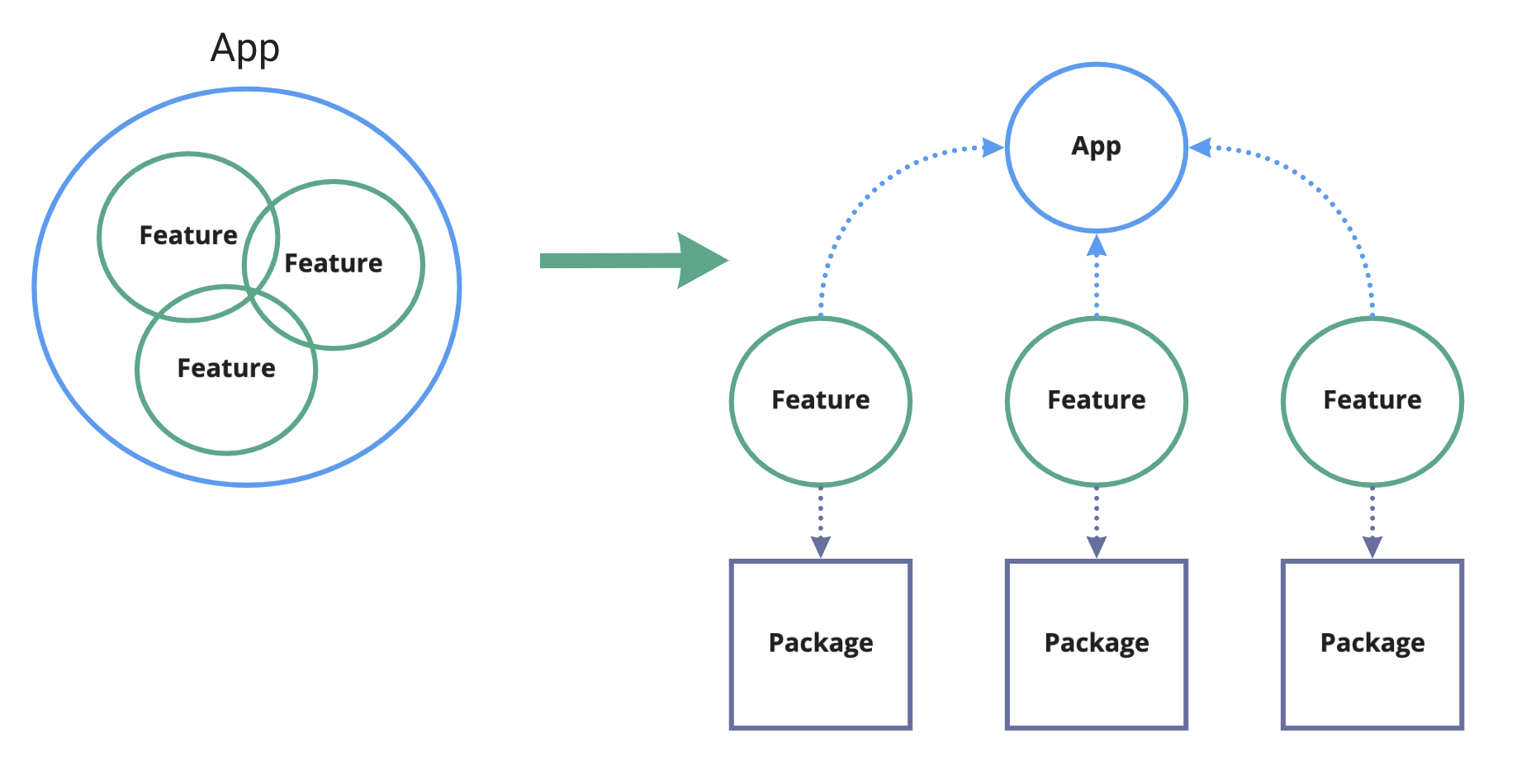
If you never worked with locally set up monorepo and now, after I mentioned “package” and “npm”, feel uneasy about the idea of publishing your private project: don’t be. Neither publishing nor open-source are a requirement for a monorepo to exist and for developers to get the benefits out of it. From the code perspective, a package is just a folder, that has package.json file with some properties. That folder is then linked via Node’s symlinks to node_modules folder, where "traditional" packages are installed. This linking is performed by tools like Yarn or Npm themselves: it’s called “workspaces”, and both of them support it. And they make packages accessible in your local code as any other package downloaded from npm.
It would look like this:
/packages/my-feature/some-folders-in-featureindex.tspackage.json // this is what defines the my-feature package/another-feature/some-folders-in-featureindex.tspackage.json // this is what defines the another-feature package
and in package.json I would have those two important fields:
{"name": "@project/my-feature","main": "index.ts"}
Where the “name” field is, obviously, the name of the package - basically the alias to this folder, through which it will be accessible to the code in the repo. And “main” is the main entry point to the package, i.e. which file is going to be imported when I write something like
import { Something } from '@project/my-feature';
There are quite a few public repositories of well-known projects that use the multi-packages monorepo approach: Babel, React, Jest to name a few.
Why packages rather than just folders
At first sight, the packages' approach looks like “just split your features into folders, what’s the big deal” and doesn’t seem that groundbreaking. There are, however, a few interesting things packages can give us, that simple folders can’t.
Aliasing. With packages, you can refer to your feature by its name, not by its location. Compare this:
import { Button } from '@project/button';
with this more “traditional” approach:
import { Button } from '../../components/button';
In the first import, it’s obvious - I’m using a generic “button” component of my project, my version of design systems.
In the second one, it’s not that clear - what is this button? Is it the generic “design systems” button? Or maybe part of this feature? Or a feature “above”? Can I even use it here, maybe it was written for some very specific use case that is not going to work in my new feature?
It gets even worst if you have multiple “utils” or “common” folders in your repo. My worst code-nightmare looks like this:
import { bla } from '../../../common';import { blabla } from '../../common';import { blablabla } from '../common';
With packages it could look something like this instead:
import { bla } from '@project/button/common';import { blabla } from '@project/something/common';import { blablabla } from '@project/my-feature/common';
Instantly obvious what comes from where, and what belongs where. And chances are, the “my-feature” “common” code was written just for the feature’s internal use, was never meant to be used outside of the feature, and re-using it somewhere else is a bad idea. With packages, you’ll see it right away.
Separation of concerns. Considering that we all are used to the packages from npm and what they represent, it becomes much easier to think about your feature as an isolated module with its own public API when it is written as a “package” right away.
Take a look at this:
import { dateTimeConverter } from '../../../../button/something/common/date-time-converter';
vs this:
import { dateTimeConverter } from '@project/button';
The first one will likely be lost in all the imports around it and slip unnoticed, turning your code into The Big Ball of Mud. The second will instantly and naturally raise a few eyebrows: a date-time converter? From a button? Really? Which will naturally force more clear boundaries between different features/packages.
Built-in support. You don’t need to invent anything, most of the modern tools, like IDE, typescript, linting or bundlers support packages out-of-the-box.
Refactoring is a breeze. With features separated into packages refactoring becomes enjoyable. Want to refactor the content of your package? Go ahead, you can re-write it fully, as long as you keep the entry’s API the same the rest of the repo won’t even notice it. Want to move your package to another location? It’s just drag-and-drop of a folder if you don’t rename it, the rest of the repo is not affected. Want to re-name the package? Just search & replace a string in the project, nothing more.
Explicit entry points. You can be very specific about what exactly from a package is available to the outside consumers if you want to truly embrace the “only public API for the consumers” mindset. For example, you can restrict all the “deep” imports, make things like @project/button/some/deep/path impossible and force everyone to only use explicitly defined public API in index.ts file. Take a look at Package entry points and Package exports docs for examples of how it works.
How to split code into packages
The biggest thing that people struggle with in multi-package architecture, is what is the right time to extract code into a package? Should every small feature be one? Or maybe packages are only for big things like a whole page or even an app?
In my experience, there is a balance here. You don’t want to extract every little thing into a package: you’ll end up with just a flat list of hundreds of one-file only tiny packages with no structure, which kinda defeats the purpose of introducing them in the first place. At the same time, you wouldn’t want your package to become too big: you’ll hit all the problems that we’re trying to solve here, only within that package.
Here are some boundaries that I usually use:
- “design system” type of things like buttons, modal dialogs, layouts, tooltips, etc, all should should be packages
- features in some “natural” UI boundaries are good candidates for a package - i.e. something that lives in a modal dialog, in a drawer, in a slide-in panel, etc
- “shareable” features - those that can be used in multiple places
- something that you can describe as an isolated “feature” with clear boundaries, logical and ideally visible in the UI
Also, same as in the previous article about how to split code into components, it’s very important for a package to be responsible only for one conceptual thing. A package, that exports a Button, CreateIssueDialog and DateTimeConverter does too many things at once and needs to be split up.
How to organize packages
Although it is possible to just create a flat list of all the packages, and for certain types of projects it would work, for large UI-heavy products it likely won’t be enough. Seeing something like “tooltip” and “settings page” packages sitting together makes me cringe. Or worse - if you have “backend” and “frontend” packages together. This is not only messy but also dangerous: the last thing that you want is to accidentally pull some “backend” code into your frontend bundle.
The actual repo structure would heavily depend on what exactly is the product you’re implementing (or even how many products are there), do you have backend or frontend only, and likely will change and evolve significantly over time. Fortunately, this is the huge advantage of packages: the actual structure is completely independent of code, you can drag-and-drop and re-structure them once a week without any consequences if there is a need.
Considering that the cost of “mistake” in the structure is quite low, there is no need to over-think it, at least at the beginning. If your project is frontend-only, you can even start with a flat list:
/packages/button.../footer/settings...
and evolve it over time into something like this:
/packages/core/button/modal/tooltip.../product-one/footer/settings.../product-two...
Or, if you have a backend, it could be something like this:
/packages/frontend... // the same as above/backend... // some backend-specific packages/common... // some packages that are shared between frontend and backend
Where in “common” you’d put some code that is shared between frontend and backend. Typically it will be some configs, constants, lodash-like utils, shared types.
How to structure a package itself
To summarise the big section above: “use monorepo, extract features into packages”. 🙂 Now to the next part - how to organize the package itself. Three things are important here for me: naming convention, separating the package into distinct layers, and strict hierarchy.
Naming convention
Everyone love naming things and debating over how bad others are at naming things, isn’t it? To reduce time wasted on endless GitHub comments threads and calm down poor geeks with code-related OCD like me, it’s better to just agree on a naming convention once for everyone.
Which one to use doesn’t really matter in my opinion, as long as it's followed throughout the project consistently. If you have ReactFeatureHere.ts and react-feature-here.ts in the same repo, a kitten cries somewhere 😿. I usually use this one:
/my-feature-name/assets // if I have some images, then they go into their own folderlogo.svgindex.tsx // main feature codetest.tsx // tests for the feature if neededstories.tsx // stories for storybooks if I use themstyles.(tsx|scss) // I like to separate styles from component's logictypes.ts // if types are shared between different files within the featureutils.ts // very simple utils that are used *only* in this featurehooks.tsx // small hooks that I use *only* in this feature
If a feature has a few smaller components that are imported directly into index.tsx, they would look like this:
/my-feature-name... // the same as beforeheader.tsxheader.test.tsxheader.styles.tsx... // etc
or, more likely, I would extract them into folders right away and they would look like this:
/my-feature-name... // index the same as before/headerindex.tsx... // etc, exactly the same naming here/footerindex.tsx... // etc, exactly the same naming here
Folders approach is much more optimized for copy-paste driven development 😊: when creating a new feature by copy-pasting structure from the feature nearby, all you’d need to do is to rename only one folder. All the files will be named exactly the same. Plus it’s easier to create a mental model of the package, to refactor and move code around (on that in the next section).
Layers within a package
A typical package with a complicated feature would have a few distinct “layers”: at least “UI” layer and “Data” layer. While it’s probably possible to mix everything together, I would still recommend against that: rendering buttons and fetching data from the backend are vastly different concerns. Separating them will give the package more structure and predictability.
And in order for the project to stay relatively healthy architecture- and code-wise, the crucial thing is to be able to clearly identify those layers that are important for your app, map the relationship between them, and organise all of this in a way that is aligned with whatever tools and frameworks are used.
If I was implementing a React project from scratch today, with Graphql for data manipulations and pure React state for state management (i.e. no Redux or any other library), I would have the following layers:
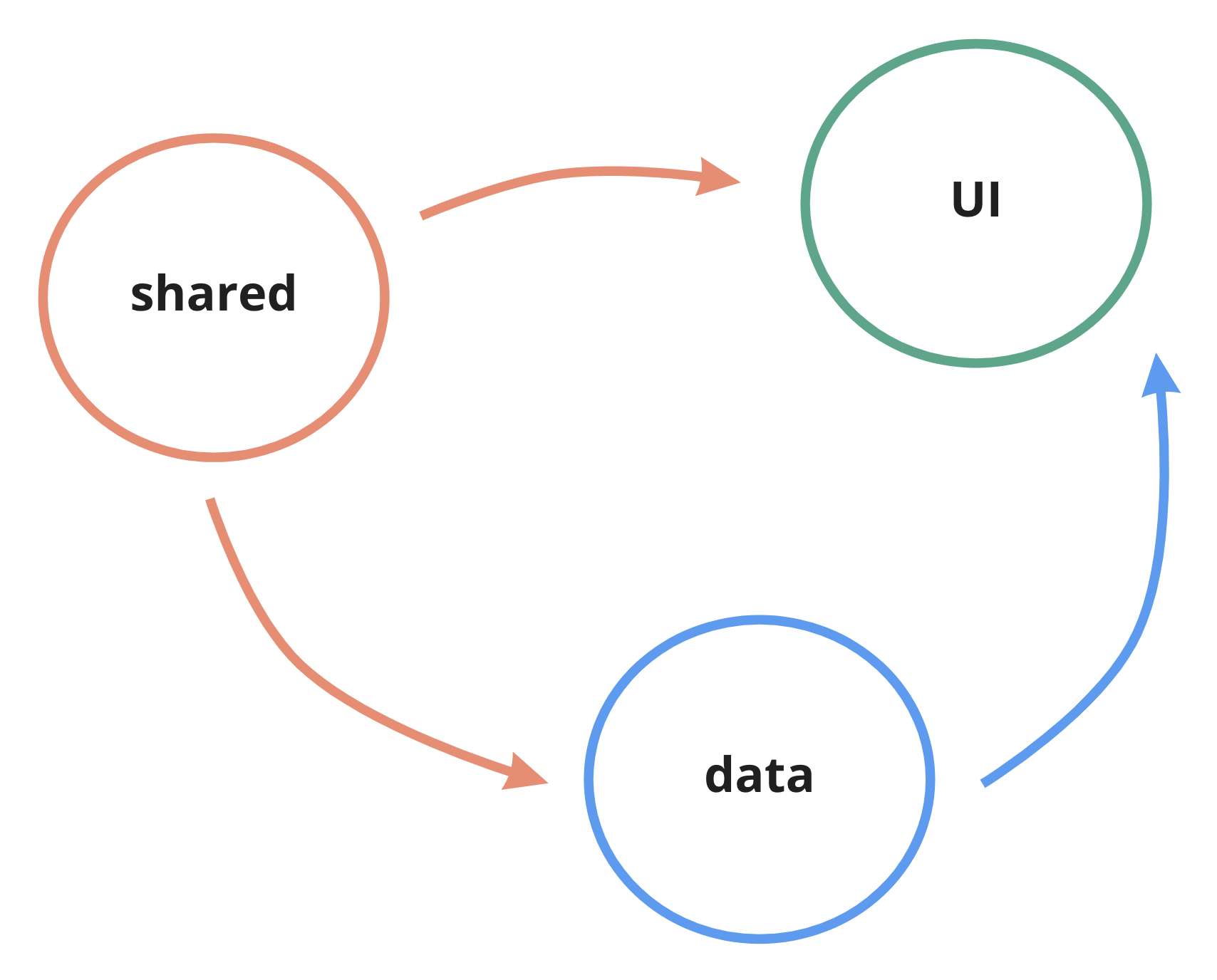
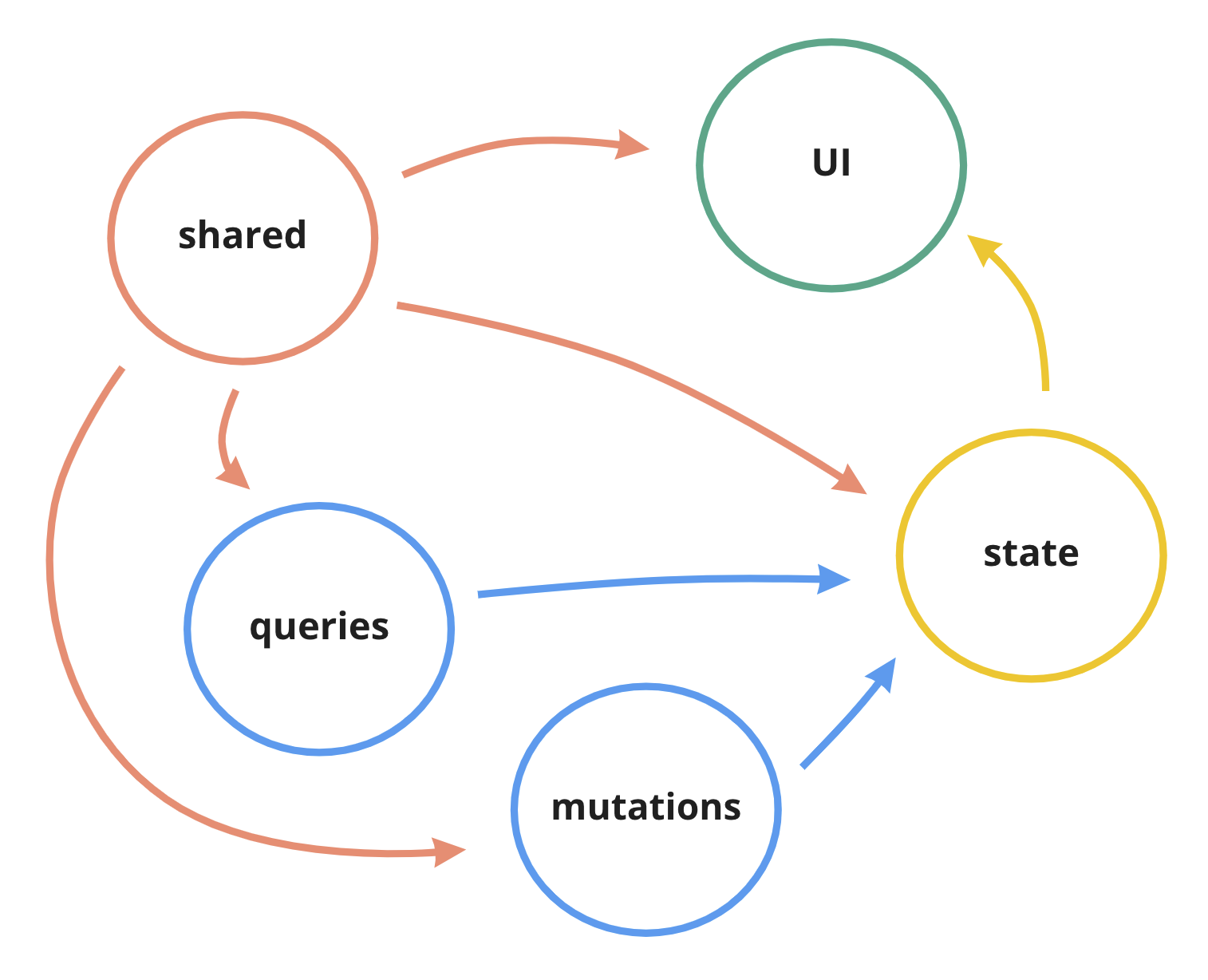
- “data” layer - queries, mutation and other things that are responsible for connecting to the external data sources and transforming it. Used only by UI layer, doesn’t depend on any other layers.
- “shared” layer - various utils, functions, hooks, mini-components, types and constants that are used across the entire package by all other layers. Doesn’t depend on any other layers.
- “ui” layer - the actual feature implementation. Depends on “data” and “shared” layers, no-one depends on it
That’s it!
If I was using some external state management library, I would probably add “state” layer as well. That one would likely be a bridge between “data” and “ui”, and therefore would use “shared” and “data” layers and “UI” would use “state” instead of “data”.
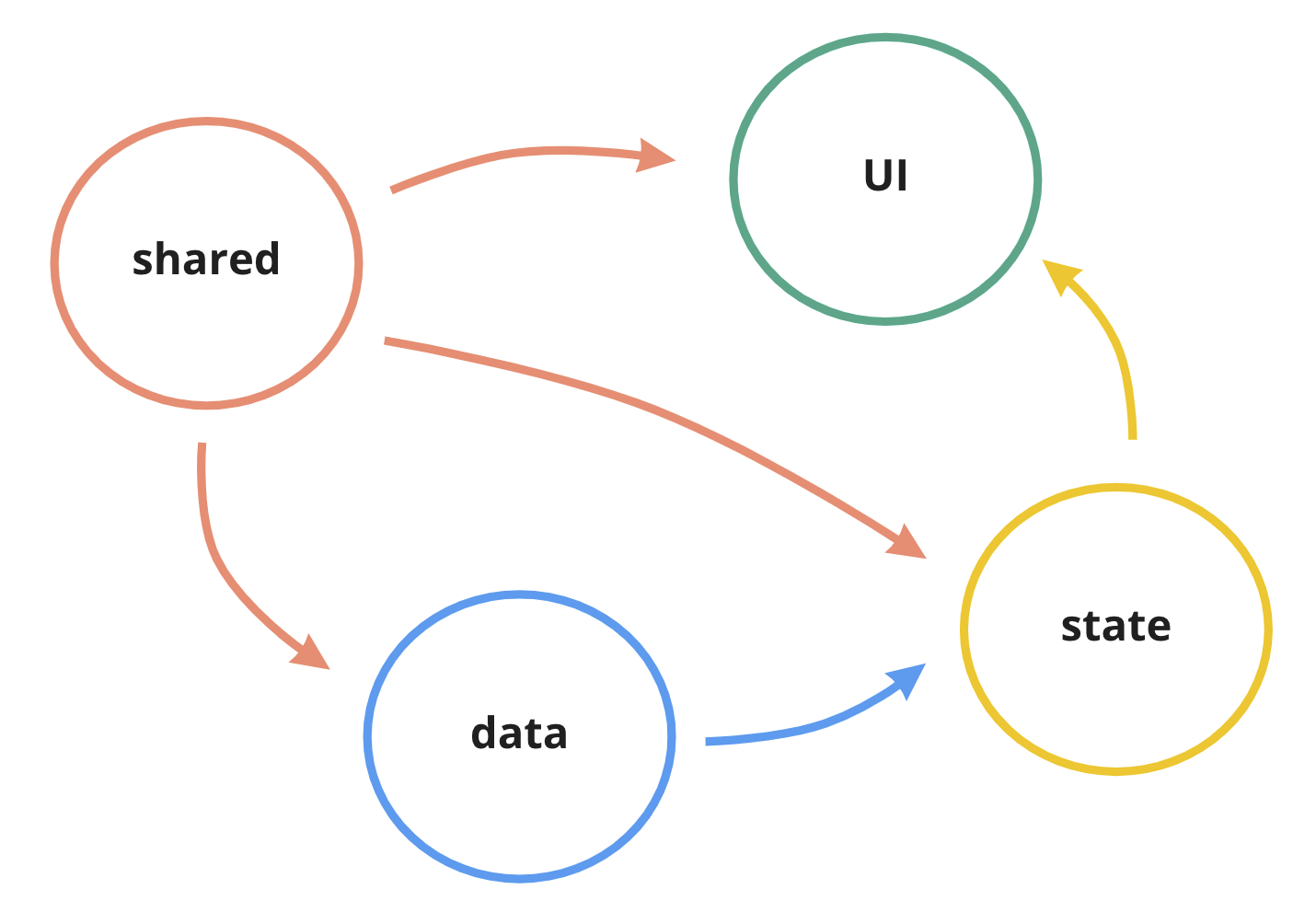
And from the implementation details point of view, all layers are top-level folders in a package:
/my-feature-package/shared/ui/dataindex.tspackage.json
With every “layer” using the same naming convention described above. So your “data” layer would look something like this:
/dataindex.tsget-some-data.tsget-some-data.test.tsupdate-some-data.tsupdate-some-data.test.ts
For more complicated packages, I might split those layers apart, while preserving their purpose and the characteristics. “Data” layer could be split into “queries” (“getters”) and “mutations” (“setters”) for example, and those can either live still in the “data” folder or move up:
/my-feature-package/shared/ui/queries/mutationsindex.tspackage.json
Or you could extract a few sub-layers from the “shared” layer, like “types” and “shared UI components” (which would instantly turn this sub-layer into “UI” type btw, since no one other than “UI” can use UI components).
/my-feature-package/shared-ui/ui/queries/mutations/typesindex.tspackage.json
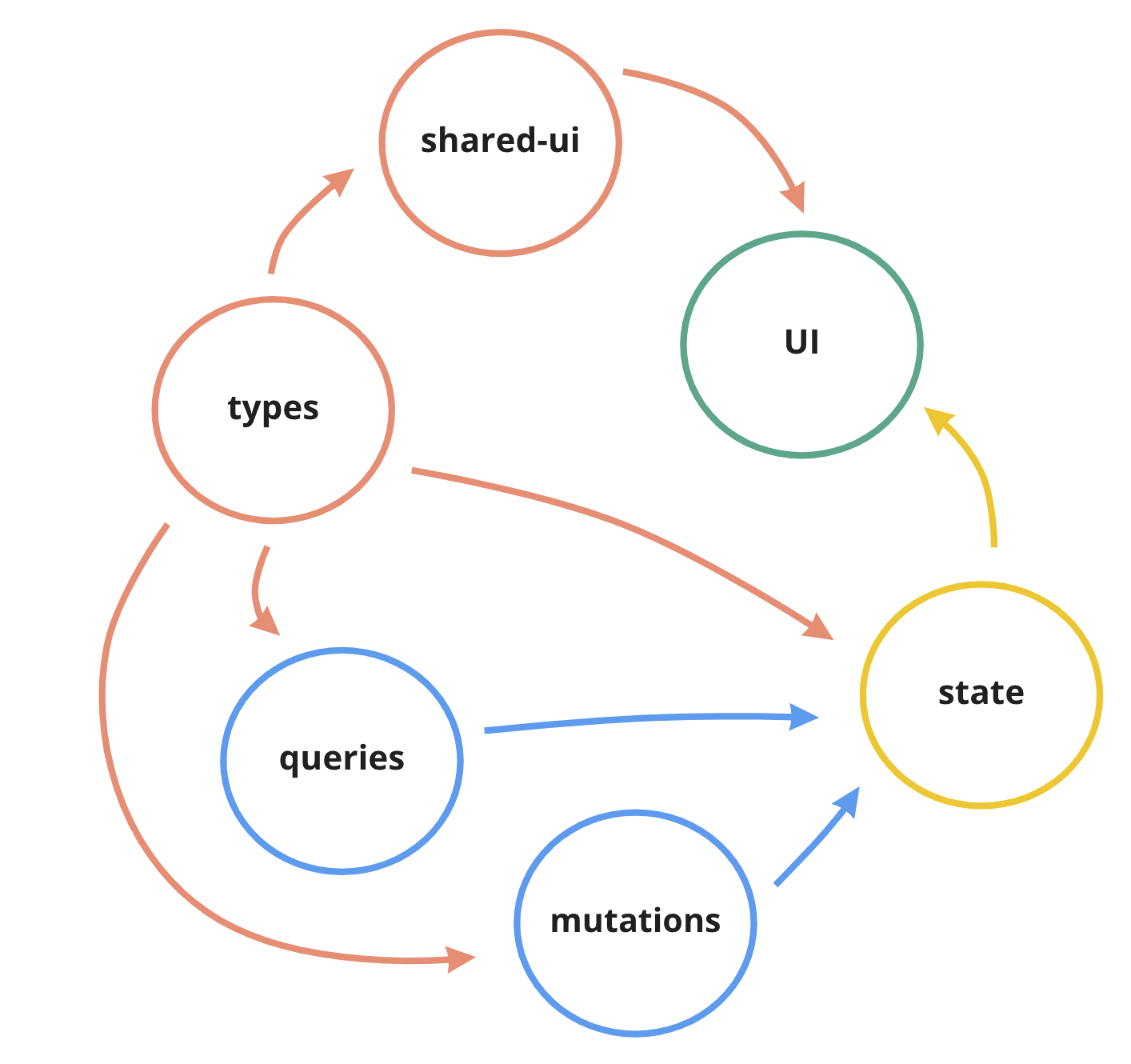
As long as you are can clearly define what’s every “sub-layer” purpose is, clear about which “sub-layer” belongs to which “layer” and can visualise and explain it to everyone in the team - everything works!
Strict hierarchy within layers
The final piece of the puzzle, which makes this architecture predictable and maintainable, is a strict hierarchy within the layers. This is going to be especially visible in the UI layer since in React apps it usually is the most complicated one.
Let’s start, for example, scaffolding a simple page, with a header and a footer. We’d have “index.ts” file - the main file, where the page comes together, and “header.ts” and “footer.ts” components.
/my-pageindex.tsheader.tsfooter.ts
Now, all of them will have their own components that I'd want to put in their own files. “Header”, for example, will have “Search bar” and “Send feedback” components. In the “traditional” flat way to organize apps we’d put them next to each other, isn’t it? Would be something like this:
/my-pageindex.tsheader.tsfooter.tssearch-bar.tssend-feedback.ts
And then, if I want to add the same “send-feedback” button to the footer component, I’d again just import it to “footer.ts” from “send-feedback.ts”, right? After all, it’s nearby and seems natural.
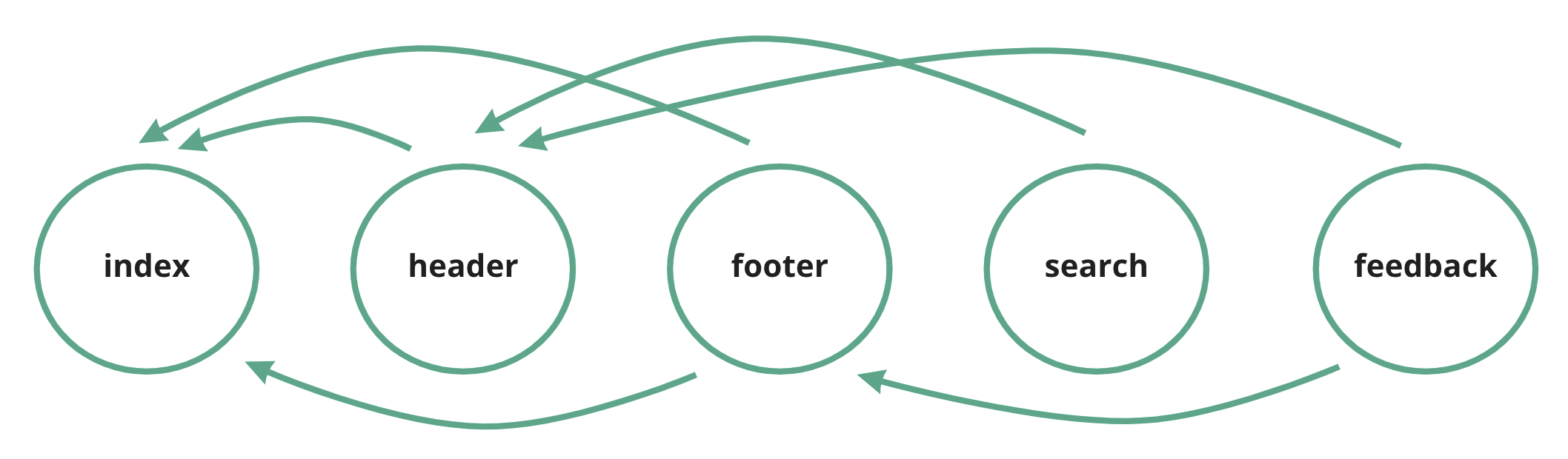
Unfortunately, what just happened, is we violated the boundaries between our layers (“UI” and “shared”) without even noticing it. If I keed adding more and more components to this flat structure, and I probably will, real applications tend to be quite complicated, I’ll likely violate them a few times more. This will turn this folder into its own tiny “Ball Of Mud”, where it’s completely unpredictable which component depends on which. And as a result, untangling all of this and extracting something out of this folder, when the refactoring time comes, might turn into a very head-scratchy exercise.
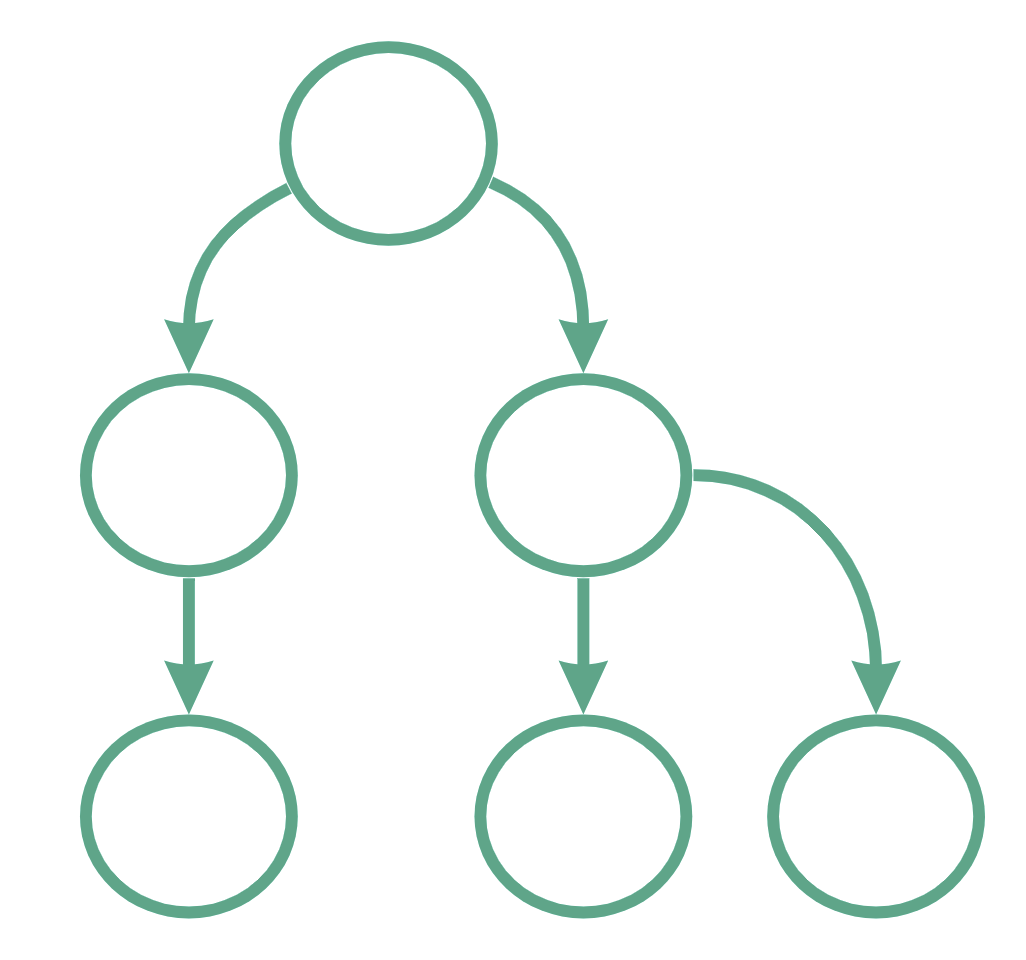
Instead, we can structure this layer in a hierarchical way. The rules are:
- only main files (i.e. “index.ts”) in a folder can have sub-components (sub-modules) and can import them
- you can import only from the “children”, not from “neighbours”
- you can not skip a level and can only import from direct children
Or, if you prefer visual, it’s just a tree:
And if you need to share some code between different levels of this hierarchy (like our send-feedback component), you’d instantly see that you’re violating the rules of hierarchy, since wherever you put it, you’d have to import it either from parents or from neighbours. So instead, it would be extracted into the “shared” layer and imported from there.
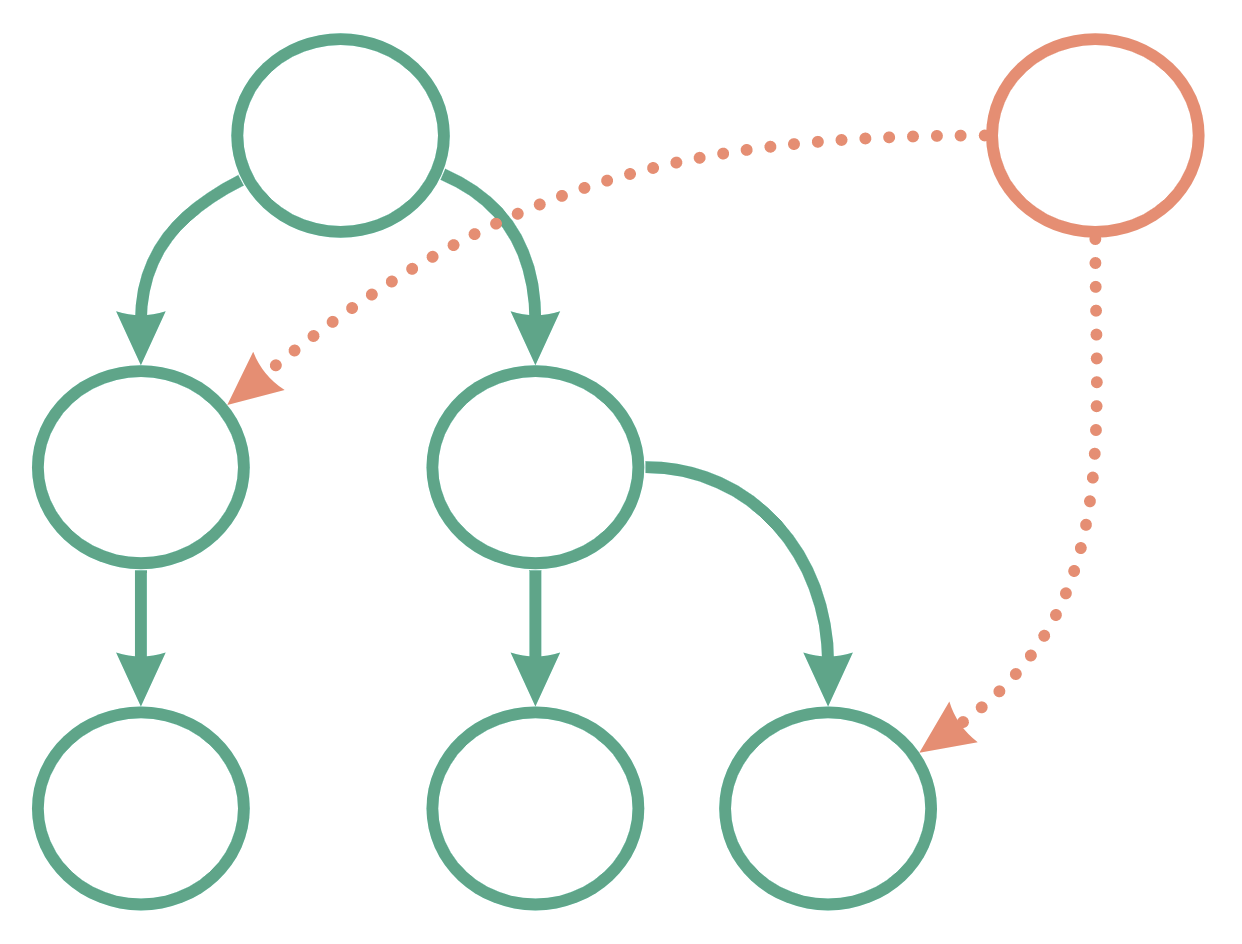
Would look like this:
/my-page/sharedsend-feedback.ts/uiindex.ts/headerindex.tssearch-bar.ts/footerindex.ts
That way the UI layer (or any layer where that rule applies) just turns into a tree structure, where every branch is independent of any other branch. Extracting anything from this package is now a breeze: all you need to do is to drag and drop a folder into a new place. And you know for sure, that not a single component in the UI tree will be affected by it except the one that actually uses it. The only thing that you might need to deal with additionally is the “shared” layer.
The full app with data layer would then look like this:
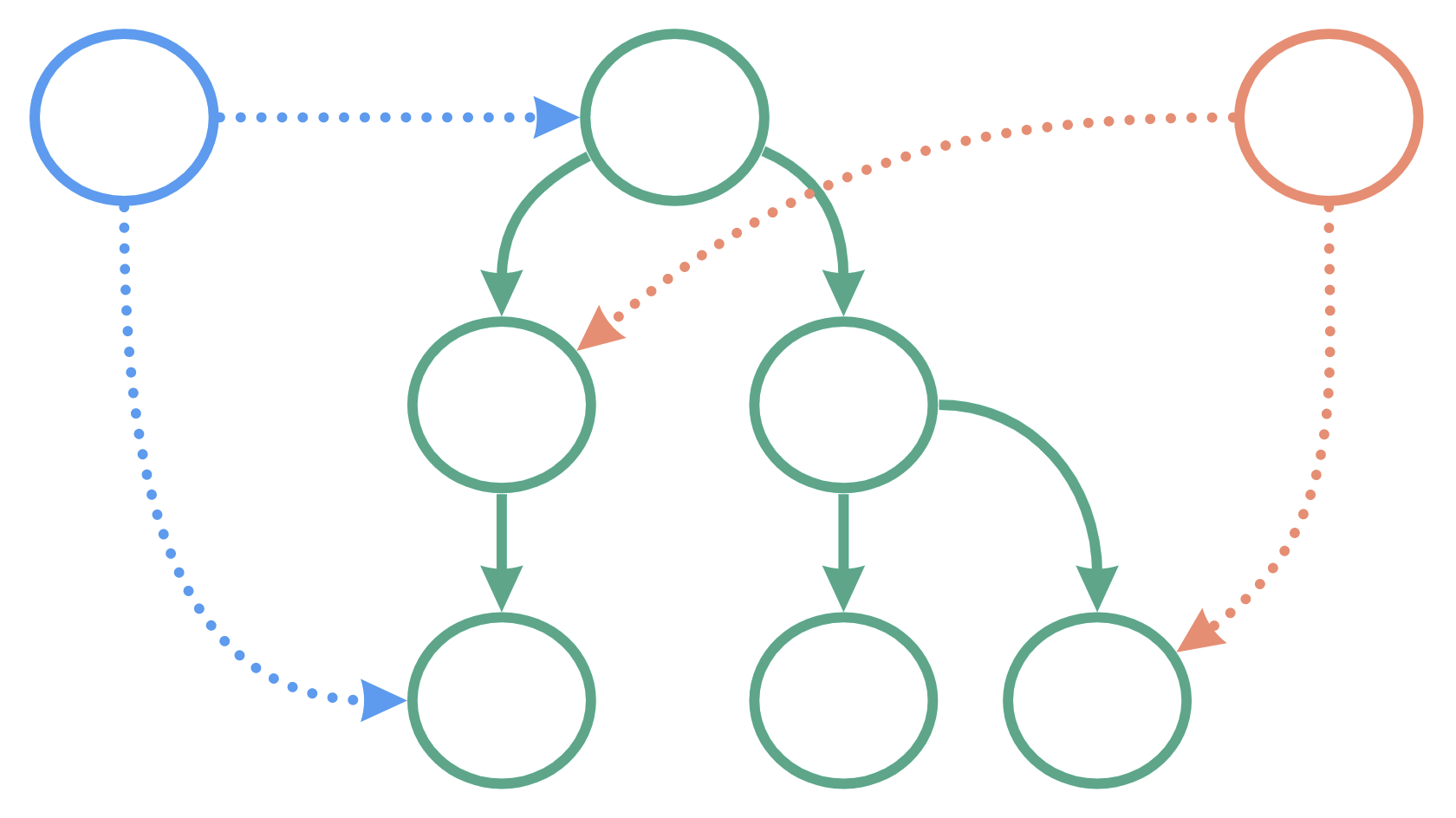
A few clearly defined layers, that are completely encapsulated and predictable.
/my-page/sharedsend-feedback.ts/dataget-something.tssend-something.ts/uiindex.ts/headerindex.tssearch-bar.ts/footerindex.ts
React recommends against nesting
If you read React docs on recommended project structure, you’ll see that React actually recommends against too much nesting. The official recommendation is “consider limiting yourself to a maximum of three or four nested folders within a single project”. And this recommendation is very relevant for this approach as well: if your package becomes too nested, it’s a clear sign that you might need to think about splitting it into smaller packages. 3-4 levels of nesting, in my experience, is enough even for very complicated features.
The beauty of packages architecture though, is that you can organize your packages with as much nesting as you need without being bound by this restriction - you never refer to another package via its relative path, only by its name. A package by the name @project/change-setting-dialog that lives at the path packages/change-settings-dialog or is hidden inside /packages/product/features/settings-page/change-setting-dialog, will be referred to as @project/change-setting-dialog regardless of its physical location.
Monorepo management tool
It’s impossible to talk about multi-packages monorepo for your architecture without touching at least a little bit on monorepo management tools. The biggest problem is usually dependency management within it. Imagine, if some of your monorepo packages use an external dependency, lodash for example.
/my-feature-onepackage.json // this one uses lodash@3.4.5/my-other-featurepackage.json // this one uses lodash@3.4.5
Now lodash releases a new version, lodash@4.0.0, and you want to move your project to it. You would need to update it everywhere at the same time: the last thing that you want is for some of the packages remaining on the old version, while some using the new one. If you’re on npm or old yarn, that would be a disaster: they would install multiple copies (not two, multiple) of lodash in your system, which will result in increasing install and build times, and your bundle sizes going through the roof. Not to mention the fun of developing a new feature when you’re using two different versions of the same library all over the project.
I’m not going to touch on what to use if your project is going to be published on npm and open-sourced: probably something like Lerna would be enough, but that is a completely different topic.
If, however, your repo is private, things are getting more interesting. Because all that you actually need in order for this architecture to work is packages “aliasing”, nothing more. I.e. just basic symlinking that both Yarn and Npm provide through the idea of workspaces. It looks like this. You have the “root” package.json file, where you declare where workspaces (i.e. your local packages):
{"private": true,"workspaces": ["packages/**"]}
And then next time you run yarn install all packages from the folder packages will turn into “proper” packages and will be available in your project via their name. That’s the whole monorepo setup!
As for dependencies. What will happen, if you have the same dependency in a few packages?
/packages/my-feature-onepackage.json // this one uses lodash@3.4.5/my-other-featurepackage.json // this one uses lodash@3.4.5
When you run yarn install it will “hoist” that package to the root node_modules:
/node_moduleslodash@3.4.5/packages/my-feature-onepackage.json // this one uses lodash@3.4.5/my-other-featurepackage.json // this one uses lodash@3.4.5
This is exactly the same situation as if you just declare lodash@3.4.5 in the root package.json only. What I’m saying is, and I will probably be buried alive by the purists of the internet for that, including myself two years ago: you don’t need to declare any of the dependencies in your local packages. Everything can just go to the root package.json. And your package.json files in local packages will be just very lightweight json files, that only specify “name” and “main” fields.
Much easier set-up to manage, especially if you’re just starting.
React project structure for scale: final overview
Huh, that was a lot of text. And even that is just a short overview: so many more things can be said on the topic! Let’s recap what has already been said at least:
Decomposition is the key to successfully scaling your react app. Think of your project not as a monolithic “project”, but as a combination of independent black-box like “features” with their own public API for the consumers to use. The same discussion as “monolith” vs “microservices” really.
Monorepo architecture is perfect for that. Extract your features into packages; organise your packages in the way that works best for your project.
Layers within one package are important to give it some structure. You’ll probably have at least “data” layer, “UI” layer and “shared” layer. Can introduce more, depending on your needs, just need to have clear boundaries between them.
Hierarchical structure of a package is cool. It makes refactoring easier, forces you to have clearer boundaries between layers, and forces you to split your package into smaller ones when it becomes too big.
Dependency management in a monorepo is a complicated topic, but if your project is private you don’t need to actually worry about it. Just declare all your dependencies in the root package.json and keep all local packages free from them.
You can take a look at the implementation of this architecture in this example repo: https://github.com/developerway/example-react-project. This is just a basic example to demonstrate the principles described in the article, so don’t be scared by tiny packages with just one index.ts: in a real app they will be much bigger.
That is all for today. Hope you’ll be able to apply some of those principles (or even all of them!) to your apps and see improvements in your day-to-day development right away! ✌🏼